Аббревиатура NLP расшифровывается как Обработка естественного языка и описывает техники и методы машинной обработки естественного языка. Цель — прямое общение между людьми и компьютерами на основе естественного языка. Как правило, обработка основана на уровне интеллекта машины, которая расшифровывает человеческие сообщения в значимую для нее информацию.
Приложения, использующие НЛП, окружают нас повсюду. К ним относятся поиск в Google, машинный перевод, чат-боты, виртуальные помощники и т. Д. Если вам нужна профессиональная помощь в интеграции любой из техник НЛП в ваш бизнес-проект, вот ссылка на веб-сайт разработчика ML.
НЛП используется в цифровой рекламе, безопасности и многих других. Технологии НЛП используются как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и его развития, а также создания “умных” систем, работающих с естественными человеческими языками, от поисковых систем до музыкальных приложений.
Одна из задач языкового моделирования — предсказать следующее слово на основе знания предыдущего текста. Это необходимо для исправления опечаток, автозаполнения, чат-ботов и т. Д. Специально для разработчиков мы собрали четыре популярные модели НЛП в одном месте и сравнили их, опираясь на документацию и научные источники. Помните, что это не единственные доступные модели НЛП, они просто самые известные и популярные среди разработчиков.
1. БЕРТ
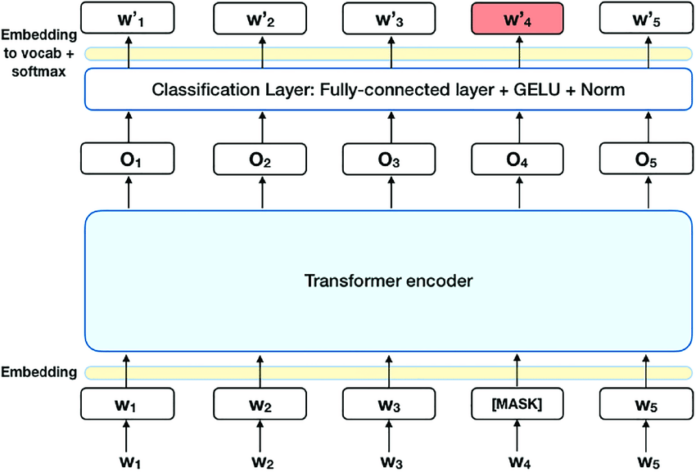
BERT опирается на нейронные сети и предназначен для улучшения понимания запросов на естественном языке и намерений пользователя, стоящих за ними. Это помогает поисковой системе определять значение слов с учетом контекста всего предложения. Его реализация должна позволить поиску научиться находить более релевантные веб-страницы, а пользователям задавать более естественные запросы.
BERT имеет открытый исходный код, доступен для исследований и может использоваться для обучения других систем анализа языка.
Ключевой особенностью BERT является двунаправленное обучение. Традиционные алгоритмы для лучшего понимания значения и значимости фразы проверяют последовательность слов в предложении только в одном направлении (слева направо или справа налево). В отличие от этого, БЕРТ анализирует все содержание предложения – как до, так и после слова, включая предлоги и отношения между словами. Такая модель может точнее определять смысл запроса, учитывая весь контекст и решая конкретные задачи пользователя.
Использование BERT сделает поиск в Google в целом более эффективным, в первую очередь для длинных запросов на естественном разговорном языке, особенно для фраз с предлогами.
Однако BERT — не единственная сеть DL, которая показывает отличные результаты в решении задач НЛП, хотя она может быть самой популярной. Многие модели НЛП основаны на БЕРТЕ; мы поговорим о них позже.
2. GPT-3 от OpenAI
GPT-3 — самая известная из современных нейросетевых моделей языка. Вы можете найти много мифов об этом, но модель знает, как произвести впечатление. Она отлично справляется с написанием эссе на заданную тему, успешно отвечает на вопросы, а также пишет стихи и программный код.
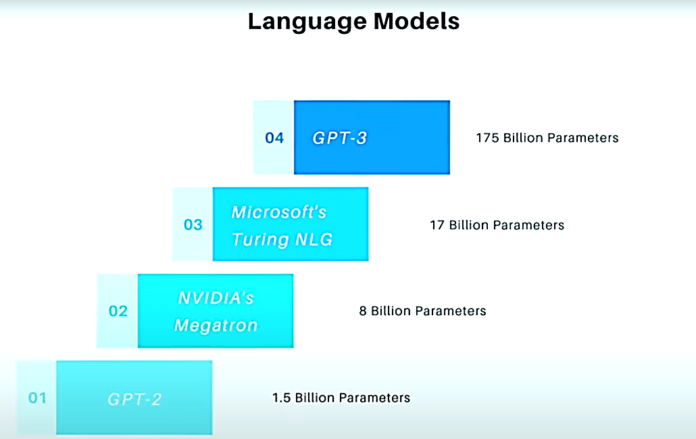
Модель GPT-3 основана на той же архитектуре, что и предыдущая модель GPT-2, но в 116 раз сложнее: она использует 175 миллиардов параметров — вторая по мощности языковая модель Microsoft Turing-NLG содержит 17 миллиардов параметров, GPT-2 — 1,5 миллиарда.
GPT-3 обучается на 570 ГБ текстовой информации, а размер обученной модели составляет около 700 ГБ. Обучающий массив включает данные из открытой библиотеки Common Crawl, всю Википедию, наборы данных с книгами и полезные тексты с сайтов WebText.
В результате модель может писать тексты на английском языке, которые практически неотличимы от человеческого уровня — по этой причине OpenAI не открывает полный доступ к модели, поскольку боится, что технология будет использована для дезинформации. В июне 2020 года OpenAI открыла частный доступ к инструментам разработчика (API) и модели GPT-3, представила свои примеры использования алгоритма и запустила “игровую площадку”.
3. Роберта

RoBERTa — это название оптимизированного подхода к предварительному обучению, разработанного Facebook и Вашингтонским университетом. RoBERTa полностью основана на BERT и изменяет некоторые методы и параметры обучения.
Цель Роберты — оптимизировать предварительное обучение с сокращением времени. Некоторые методы и параметры BERT были изменены и адаптированы для предварительного обучения. Например, разработчики исключили предсказание следующего предложения из предварительного обучения и ввели динамическую маскировку. Кроме того, разработчики в десять раз увеличили объем обучающих данных и увеличили количество итераций обучения. РоБЕРТа добилась отличных результатов в различных тестах НЛП.
Оптимизация предварительного тренинга Берта с Робертой показывает значительные улучшения в различных тестах НЛП по сравнению с оригинальным тренингом Берта. В таких тестах НЛП, как «КЛЕЙ», «Отряд» или «ГОНКА», Роберта достигла ранее недостижимых высоких результатов. Например, Роберта набрала 88,5 баллов в тесте GLUE. Роберта также превзошла XLNet и BERT в тесте RACE. Результаты доказывают, что оптимизация с помощью RoBERTa может значительно повысить производительность языковых моделей для различных задач NLP.
4. КодеБЕРТ
CodeBERT — это модель NLP от Microsoft, основанная на BERT. Трансформаторы содержат математические функции, расположенные во взаимосвязанных слоях, передают сигналы из входных данных и регулируют синаптическую мощность любого соединения, как и во всех нейронных сетях. Все модули искусственного интеллекта извлекают функции и обучаются для создания мониторинга, о котором заботятся трансформаторы, например, о том, чтобы любой выход был подключен к входному компоненту. Веса между ними рассчитываются динамически.
Исследователи говорят, что Code BERT добился высокой производительности как при поиске кода на естественном языке, так и при разработке кода для документации. В предстоящей работе они намерены изучить лучшие поколения и более сложную нейтральную архитектуру и изучить цели, связанные с новым поколением.
Заключение
Каждое улучшение языковых моделей способствует развитию NLP, от Word2vec до ELMo, от OpenAI GPT до BERT. Благодаря этим разработкам мы также можем понять, что глубокое обучение как репрезентативное обучение будет все чаще применяться к задачам НЛП в будущем. Они могут в полной мере использовать текущие массивные данные, комбинировать различные сценарии задач и обучать более продвинутые модели для облегчения проектов ИИ. Благодаря хорошо внедренному решению NLP организации могут обеспечить более глубокое понимание неструктурированных данных, расширяя возможности бизнес-аналитики.